Architecture overview
ECMP distributes packets for a VIP evenly to Maglev forwarders. Maglev then implements the return path with Direct Server Return, directly sending packets from service endpoint to the edge routers.
A Maglev cluster can be sharded by serving different sets of VIPs on each shard, which improves scalability and performance isolation between tenants.

Maglev configuration
Maglev services retrieve configuration objects from local files or remote RPC.
In the diagram below, BP stands for backend pool, and represents a set of service endpoints (generally TCP or UDP servers). BPs can include other BPs to simplify configuration of a common set of backends.
Maglev services
Maglev runs on commodity Linux servers. It achieves 10Gbps line-rate throughput via kernel bypass, share-nothing architecture and other optimization techniques.

Each Maglev machine contains a controller and a forwarder.
Maglev controller
A Maglev controller announces VIPs defined in its config objects, and withdraws all VIP announcements when the forwarder becomes unhealthy. This ensures that routers only forward packets to healthy machines.
Maglev forwarder
Health checking
Each BP is associated with one or more health checking methods, and health checks are deduplicated by IP to reduce overhead. Only healthy backends are considered for consistent hashing.
Packet flow
- Packets are read by the steering module from the shared packet pool, and distributed to packet (rewriter) threads with 5-tuple hashing.
- Packets are rewritten to be GRE-encapsulated, with the outer IP header destined to the selected backend. Selection is done via connection tracking and consistent hashing.
- Rewritten packets are send to TX queues, which are polled by the muxing module and passed to the NIC via the shared packet pool.
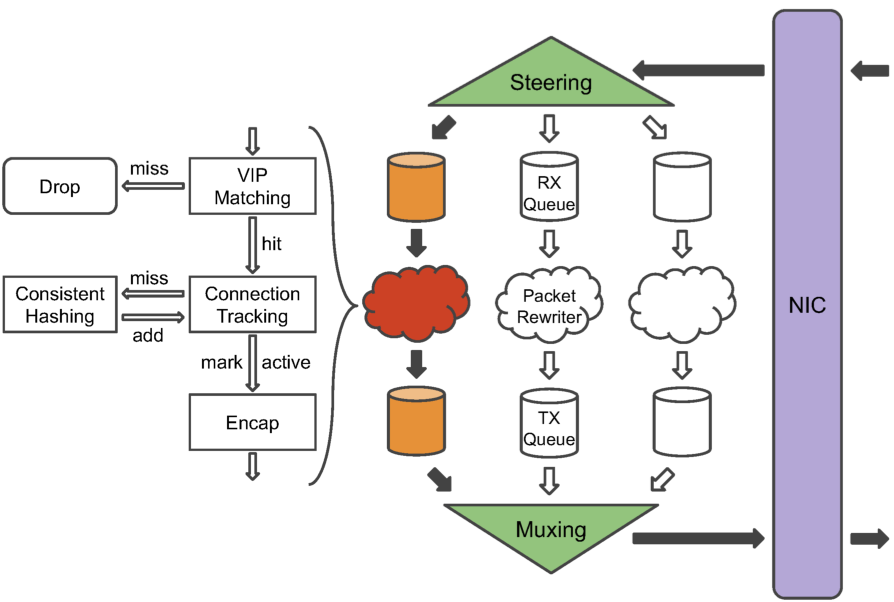
The shared packet pool between the NIC and the forwarder means that packets do not need to be copied for transmit or receive. A ring queue of pointers also makes it possible to process packets in batches, further improving efficiency.

Consistent hashing
Maglev favors even load balancing over minimal disruption during backend changes in its consistent hashing algorithm. Maglev achieves an over-provision factor of less than 1.2 over 60% of time in a production cluster.
Config updates are committed atomically, so that consistent hashing input (set of backends) only changes once. Configuration of different machines may be temporarily out of sync, due to the nature of distributed systems.
Connection tracking
Connection tracking state is stored locally on each thread of a Maglev machine. It helps when the set of backends change, but is insufficient for the following cases.
- When the set of Maglev machines changes, the router in front might not provide connection affinity. This behavior is vendor-specific and out of Maglev’s control.
- During heavy load or SYN flood attacks, the connection tracking table may be filled and could not track new connections.
In such cases, consistent hashing is used as a fallback, which is sufficient if backends do not change in the meantime.
Thread optimizations
- Each thread is pinned to a dedicated CPU core to achieve maximum performance.
- Hash is recomputed on each packet thread to avoid cross-thread synchronization.